Генеральное среднее квадратическое отклонение. Среднее квадратическое отклонение
Определяется как обобщающая характеристика размеров вариации признака в совокупности. Оно равно квадратному корню из среднего квадрата отклонений отдельных значений признака от средней арифметической, т.е. корень из и может быть найдена так:
1. Для первичного ряда:
2. Для вариационного ряда:

Преобразование формулы среднего квадратичного отклонени приводит ее к виду, более удобному для практических расчетов:
Среднее квадратичное отклонение определяет на сколько в среднем отклоняются конкретные варианты от их среднего значения, и к тому же является абсолютной мерой колеблемости признака и выражается в тех же единицах, что и варианты, и поэтому хорошо интерпретируется.
Примеры нахождения cреднего квадратического отклонения: ,
Для альтернативных признаков формула среднего квадратичного отклонения выглядит так:
![]()
где р - доля единиц в совокупности, обладающих определенным признаком;
q - доля единиц, не обладающих этим признаком.
Понятие среднего линейного отклонения
Среднее линейное отклонение определяется как средняя арифметическая абсолютных значений отклонений отдельных вариантов от .
1. Для первичного ряда:

2. Для вариационного ряда:
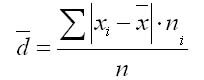
где сумма n - сумма частот вариационного ряда .
Пример нахождения cреднего линейного отклонения:
Преимущество среднего абсолютного отклонения как меры рассеивания перед размахом вариации, очевидно, так как эта мера основана на учете всех возможных отклонений. Но этот показатель имеет существенные недостатки. Произвольные отбрасывания алгебраических знаков отклонений могут привести к тому, что математические свойства этого показателя являются далеко не элементарными. Это сильно затрудняет использование среднего абсолютного отклонения при решении задач, связанных с вероятностными расчетами.
Поэтому среднее линейное отклонение как мера вариации признака применяется в статистической практике редко, а именно тогда, когда суммирование показателей без учета знаков имеет экономический смысл. С его помощью, например, анализируется оборот внешней торговли, состав работающих, ритмичность производства и т. д.
Среднее квадратическое
Среднее квадратическое применяется , например, для вычисления средней величины сторон n квадратных участков, средних диаметров стволов, труб и т. д. Она подразделяется на два вида.
Средняя квадратичная простая. Если при замене индивидуальных величин признака на среднюю величину необходимо сохранить неизменной сумму квадратов исходных величин, то средняя будет являться квадратичной средней величиной.
Она является квадратным корнем из частного от деления суммы квадратов отдельных значений признака на их число:
Средняя квадратичная взвешенная вычисляется по формуле:

где f - признак веса.
Средняя кубическая
Средняя кубическая применяется
, например, при определении средней длины стороны и кубов. Она подразделяется на два вида.
Средняя кубическая простая:


При расчете средних величин и дисперсии в интервальных рядах распределения истинные значения признака заменяются центральными значениями интервалов, которые отличны от средней арифметической значений, включенных в интервал. Это приводит к возникновению систематической погрешности при расчете дисперсии. В.Ф. Шеппард определил, что погрешность в расчете дисперсии , вызванная применением сгруппированных данных, составляет 1/12 квадрата величины интервала как в сторону повышения, так и в сторону понижения величины дисперсии.
Поправка Шеппарда должна применяться, если распределение близко к нормальному, относится к признаку с непрерывным характером вариации, построено по значительному количеству исходных данных (n > 500). Однако исходя из того, что в ряде случаев обе погрешности, действуя в разных направлениях компенсируют друг друга, можно иногда отказаться от введения поправок.
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность и тем более типичной будет средняя величина.
В практике статистики часто возникает необходимость сравнения вариаций различных признаков. Например, большой интерес представляет сравнение вариаций возраста рабочих и их квалификации, стажа работы и размера заработной платы, себестоимости и прибыли, стажа работы и производительности труда и т.д. Для таких сопоставлений показатели абсолютной колеблемости признаков непригодны: нельзя сравнивать колеблемость стажа работы, выраженного в годах, с вариацией заработной платы, выраженной в рублях.
Для осуществления таких сравнений, а также сравнений колеблемости одного и того же признака в нескольких совокупностях с разными средним арифметическим используется относительный показатель вариации - коэффициент вариации.
Структурные средние
Для характеристики центральной тенденции в статистических распределениях не редко рационально вместе со средней арифметической использовать некоторое значение признака X, которое в силу определенных особенностей расположения в ряду распределения может характеризовать его уровень.
Это особенно важно тогда, когда в ряду распределения крайние значения признака имеют нечеткие границы. В связи с этим точное определение средней арифметической, как правило, невозможно, либо очень сложно. В таких случаях средний уровень можно определить, взяв, например, значение признака, которое расположено в середине ряда частот или которое чаще всего встречается в текущем ряду.
Такие значения зависят только от характера частот т. е. от структуры распределения. Они типичны по месту расположения в ряду частот, поэтому такие значения рассматриваются в качестве характеристик центра распределения и поэтому получили определение структурных средних. Они применяются для изучения внутреннего строения и структуры рядов распределения значений признака. К таким показателям относятся .
Занятие №4
Тема: «Описательная статистика. Показатели разнообразия признака в совокупности»
Основными критериями разнообразия признака в статистической совокупности являются: лимит, амплитуда, среднее квадратическое отклонение, коэффициент осцилляции и коэффициент вариации. На предыдущем занятии обсуждалось, что средние величины дают лишь обобщающую характеристику изучаемого признака в совокупности и не учитывают значения отдельных его вариант: минимальное и максимальное значения, выше среднего, ниже среднего и т.д.
Пример. Средние величины двух разных числовых последовательностей: -100; -20; 100; 20 и 0,1; -0,2; 0,1 абсолютно одинаковы и равны О. Однако, диапазоны разброса данных этих последовательностей относительного среднего значения сильно различны.
Определение перечисленных критериев разнообразия признака прежде всего осуществляется с учетом его значения у отдельных элементов статистической совокупности.
Показатели измерения вариации признака бывают абсолютные и относительные . К абсолютным показателям вариации относят: размах вариации, лимит, среднее квадратическое отклонение, дисперсию. Коэффициент вариации и коэффициент осцилляции относятся к относительным показателям вариации.
Лимит (lim)– это критерий, который определяется крайними значениями вариант в вариационном ряду. Другими словами, данный критерий ограничивается минимальной и максимальной величинами признака:
Амплитуда (Am) или размах вариации – это разность крайних вариант. Расчет данного критерия осуществляется путем вычитания из максимального значения признака его минимального значения, что позволяет оценить степень разброса вариант:
Недостатком лимита и амплитуды как критериев вариабельности является то, что они полностью зависят от крайних значений признака в вариационном ряду. При этом не учитываются колебания значений признака внутри ряда.
Наиболее полную характеристику разнообразия признака в статистической совокупности дает среднее квадратическое отклонение (сигма), которое является общей мерой отклонения вариант от своей средней величины. Среднее квадратическое отклонение часто называют также стандартным отклонением .
В основе среднего квадратического отклонения лежит сопоставление каждой варианты со средней арифметической данной совокупности. Так как в совокупности всегда будут варианты как меньше, так и больше, чем она, то сумма отклонений , имеющих знак "", будет погашаться суммой отклонений, имеющих знак "", т.е. сумма всех отклонений равна нулю. Для того, чтобы избежать влияния знаков разностей берут отклонения вариант от среднего арифметического в квадрате, т.е. . Сумма квадратов отклонений не равняется нулю. Чтобы получить коэффициент, способный измерить изменчивость, берут среднее от суммы квадратов – это величина носит название дисперсии:

По смыслу, дисперсия – это средний квадрат отклонений индивидуальных значений признака от его средней величины. Дисперсия – квадрат среднего квадратического отклонения .
Дисперсия является размерной величиной (именованной). Так, если варианты числового ряда выражены в метрах, то дисперсия дает квадратные метры; если варианты выражены в килограммах, то дисперсия дает квадрат этой меры (кг 2), и т.д.
Среднее квадратическое отклонение – квадратный корень из дисперсии:
, то при расчете дисперсии и среднего квадратического отклонения в знаменателе дроби вместо необходимо ставить .
Расчет среднего квадратического отклонения можно разбить на шесть этапов, которые необходимо осуществить в определенной последовательности:
Применение среднеквадратического отклонения:
а) для суждения о колеблемости вариационных рядов и сравнительной оценки типичности (представительности) средних арифметических величин. Это необходимо в дифференциальной диагностике при определении устойчивости признаков.
б) для реконструкции вариационного ряда, т.е. восстановления его частотной характеристики на основе правила «трех сигм» . В интервале (М±3σ) находится 99,7% всех вариант ряда, в интервале (М±2σ) - 95,5% и в интервале (М±1σ) - 68,3% вариант ряда (рис.1).
в) для выявления «выскакивающих» вариант
г) для определения параметров нормы и патологии с помощью сигмальных оценок
д) для расчета коэффициента вариации
е) для расчета средней ошибки средней арифметической величины.
Для характеристики любой генеральной совокупности, имеющей нормальный тип распределения , достаточно знать два параметра: среднюю арифметическую и среднее квадратическое отклонение.

Рисунок 1. Правило «трех сигм»
Пример.
В педиатрии среднеквадратическое отклонение используется для оценки физического развития детей путем сравнения данных конкретного ребенка с соответствующими стандартными показателями. За стандарт принимаются средние арифметические показатели физического развития здоровых детей. Сравнение показателей со стандартами проводят по специальным таблицам, в которых стандарты приводятся вместе с соответствующими им сигмальными шкалами. Считается, что если показатель физического развития ребенка находится в пределах стандарт (среднее арифметическое) ±σ, то физическое развитие ребенка (по этому показателю) соответствует норме. Если показатель находится в пределах стандарт ±2σ, то имеется незначительное отклонение от нормы. Если показатель выходит за эти границы, то физическое развитие ребенка резко отличается от нормы (возможна патология).
Кроме показателей вариации, выраженных в абсолютных величинах, в статистическом исследовании используются показатели вариации, выраженные в относительных величинах. Коэффициент осцилляции - это отношение размаха вариации к средней величине признака. Коэффициент вариации - это отношение среднего квадратического отклонения к средней величине признака. Как правило, эти величины выражаются в процентах.
Формулы расчета относительных показателей вариации:
Из приведенных формул видно, что чем больше коэффициент V приближен к нулю, тем меньше вариация значений признака. Чем больше V , тем более изменчив признак.
В статистической практике наиболее часто применяется коэффициент вариации. Он используется не только для сравнительной оценки вариации, но и для характеристики однородности совокупности. Совокупность считается однородной, если коэффициент вариации не превышает 33% (для распределений, близких к нормальному). Арифметически отношение σ и средней арифметической нивелирует влияние абсолютной величины этих характеристик, а процентное соотношение делает коэффициент вариации величиной безразмерной (неименованной).
Полученное значение коэффициента вариации оценивается в соответствии с ориентировочными градациями степени разнообразия признака:
Слабое - до 10 %
Среднее - 10 - 20 %
Сильное - более 20 %
Использование коэффициента вариации целесообразно в случаях, когда приходится сравнивать признаки разные по своей величине и размерности.
Отличие коэффициента вариации от других критериев разброса наглядно демонстрирует пример .
Таблица 1
Состав работников промышленного предприятия
На основании приведенных в примере статистических характеристик можно сделать вывод об относительной однородности возрастного состава и образовательного уровня работников предприятия при низкой профессиональной устойчивости обследованного контингента. Нетрудно заметить, что попытка судить об этих социальных тенденциях по среднему квадратическому отклонению привела бы к ошибочному заключению, а попытка сравнения учетных признаков «стаж работы» и «возраст» с учетным признаком «образование» вообще была бы некорректной из-за разнородности этих признаков.
Медиана и перцентили
Для порядковых (ранговых) распределений, где критерием середины ряда является медиана, среднеквадратическое отклонение и дисперсия не могут служить характеристиками рассеяния вариант.
То же свойственно и для открытых вариационных рядов. Указанное обстоятельство связано с тем, что отклонения, по которым вычисляются дисперсия и σ, отсчитываются от среднего арифметического, которое не вычисляется в открытых вариационных рядах и в рядах распределений качественных признаков. Поэтому для сжатого описания распределений используется другой параметр разброса – квантиль (синоним - «nерцентиль»), пригодный для описания качественных и количественных признаков при любой форме их распределения. Этот параметр может использоваться и для перевода количественных признаков в качественные. В этом случае такие оценки присваиваются в зависимости от того, какому по порядку квантилю соответствует та или иная конкретная варианта.
В практике медико-биологических исследований наиболее часто используются следующие квантили:
– медиана;
, – квартили (четверти), где – нижний квартиль, – верхний квартиль.
Квантили делят область возможных изменений вариант в вариационном ряду на определенные интервалы. Медиана (квантиль) – это варианта, которая находится в середине вариационного ряда и делит этот ряд пополам, на две равные части (0,5 и 0,5 ). Квартиль делит ряд на четыре части: первая часть (нижний квартиль) – это варианта, отделяющая варианты, числовые значения которых не превышают 25% максимально возможного в данном ряду, квартиль отделяет варианты с числовым значением до 50% от максимально возможного. Верхний квартиль () отделяет варианты величиной до 75% от максимально возможных значений.
В случае асимметричности распределения переменной относительно среднего арифметического для его характеристики используются медиана и квартили. В этом случае используется следующая форма отображения средней величины – Ме (;). Например , исследуемый признак – «срок, в котором ребенок начал самостоятельно ходить» - в исследуемой группе имеет ассиметричное распределение. При этом, нижнему квартилю () соответствует срок начала ходьбы – 9,5 месяцев, медиане – 11 месяцев, верхнему квартилю () – 12 месяцев. Соответственно, характеристика средней тенденции указанного признака будет представлена, как 11 (9,5; 12) месяцев.
Оценка статистической значимости результатов исследования
Под статистической значимостью данных понимают степень их соответствия отображаемой действительности, т.е. статистически значимыми данными считаются те, которые не искажают и правильно отражают объективную реальность.
Оценить статистическую значимость результатов исследования – означает определить, с какой вероятностью возможно перенести результаты, полученные на выборочной совокупности, на всю генеральную совокупность. Оценка статистической значимости необходима для понимания того, насколько по части явления можно судить о явлении в целом и его закономерностях.
Оценка статистической значимости результатов исследования складывается из:
1. ошибок репрезентативности (ошибок средних и относительных величин) - m ;
2. доверительных границ средних или относительных величин;
3. достоверности разности средних или относительных величин по критерию t .
Стандартная ошибка средней арифметической или ошибка репрезентативности характеризует колебания средней. При этом необходимо отметить, что чем больше объем выборки, тем меньше разброс средних величин. Стандартная ошибка среднего вычисляется по формуле:
В современной научной литературе средняя арифметическая записывается вместе с ошибкой репрезентативности:
или вместе со среднеквадратическим отклонением:
В качестве примера рассмотрим данные по 1500 городских поликлиник страны (генеральная совокупность). Среднее число пациентов, обслуживающихся в поликлинике равно 18150 человек. Случайный отбор 10 % объектов (150 поликлиник) дает среднее число пациентов, равное 20051 человек. Ошибка выборки, очевидно связанная с тем, что не все 1500 поликлиник попали в выборку, равна разности между этими средними – генеральным средним (M ген) и выборочным средним (М выб). Если сформировать другую выборку того же объема из нашей генеральной совокупности, она даст другую величину ошибки. Все эти выборочные средние при достаточно больших выборках распределены нормально вокруг генеральной средней при достаточно большом числе повторений выборки одного и того же числа объектов из генеральной совокупности. Стандартная ошибка среднего m - это неизбежный разброс выборочных средних вокруг генеральной средней.
В случае, когда результаты исследования представлены относительными величинами (например, процентными долями) – рассчитывается стандартная ошибка доли:
![]()
где P – показатель в %, n – количество наблюдений.
Результат отображается в виде (P ± m)%. Например, процент выздоровления среди больных составил (95,2±2,5)%.
В том случае, если число элементов совокупности , то при расчете стандартных ошибок среднего и доли в знаменателе дроби вместо необходимо ставить .
Для нормального распределения (распределение выборочных средних является нормальным) известно, какая часть совокупности попадает в любой интервал вокруг среднего значения. В частности:
На практике проблема заключается в том, что характеристики генеральной совокупности нам неизвестны, а выборка делается именно с целью их оценки. Это означает, что если мы будем делать выборки одного и того же объема n из генеральной совокупности, то в 68,3% случаев на интервале будет находиться значение M (оно же в 95,5% случаев будет находиться на интервале и в 99,7% случаев – на интервале).
Поскольку реально делается только одна выборка, то формулируется это утверждение в терминах вероятности: с вероятностью 68,3% среднее значение признака в генеральной совокупности заключено в интервале, с вероятностью 95,5% - в интервале и т.д.
На практике вокруг выборочного значения строится такой интервал, который бы с заданной (достаточно высокой) вероятностью – доверительной вероятностью – «накрывал» бы истинное значение этого параметра в генеральной совокупности. Этот интервал называется доверительным интервалом .
Доверительная вероятность P – это степень уверенности в том, что доверительный интервал действительно будет содержать истинное (неизвестное) значение параметра в генеральной совокупности.
Например, если доверительная вероятность Р равна 90%, то это означает, что 90 выборок из 100 дадут правильную оценку параметра в генеральной совокупности. Соответственно, вероятность ошибки, т.е. неверной оценки генерального среднего по выборке, равна в процентах: . Для данного примера это значит, что 10 выборок из 100 дадут неверную оценку.
Очевидно, что степень уверенности (доверительная вероятность) зависит от величины интервала: чем шире интервал, тем выше уверенность, что в него попадет неизвестное значение для генеральной совокупности . На практике для построения доверительного интервала берется, как минимум, удвоенная ошибка выборки, чтобы обеспечить уверенность не менее 95,5%.
Определение доверительных границ средних и относительных величин позволяет найти два их крайних значения – минимально возможное и максимально возможное, в пределах которых изучаемый показатель может встречаться во всей генеральной совокупности. Исходя из этого, доверительные границы (или доверительный интервал) - это границы средних или относительных величин, выход за пределы которых вследствие случайных колебаний имеет незначительную вероятность.
Доверительный интервал может быть переписан в виде: , где t – доверительный критерий.
Доверительные границы средней арифметической величины в генеральной совокупности определяют по формуле:
М ген = М выб + t m M
для относительной величины:
Р ген = Р выб + t m Р
где М ген и Р ген - значения средней и относительной величины для генеральной совокупности; М выб и Р выб - значения средней и относительной величины, полученные на выборочной совокупности; m M и m P - ошибки средней и относительной величин; t - доверительный критерий (критерий точности, который устанавливается при планировании исследования и может быть равен 2 или 3); t m - это доверительный интервал или Δ – предельная ошибка показателя, полученного при выборочном исследовании.
Следует отметить, что величина критерия t в определенной мере связана с вероятностью безошибочного прогноза (р), выраженной в %. Ее избирает сам исследователь, руководствуясь необходимостью получить результат с нужной степенью точности. Так, для вероятности безошибочного прогноза 95,5% величина критерия t составляет 2, для 99,7% - 3.
Приведенные оценки доверительного интервала приемлемы лишь для статистических совокупностей с количеством наблюдений более 30. При меньшем объеме совокупности (малых выборках) для определения критерия t пользуются специальными таблицами. В данных таблицах искомое значение находится на пересечении строки, соответствующей численности совокупности (n-1) , и столбца, соответствующего уровню вероятности безошибочного прогноза (95,5%; 99,7%), выбранному исследователем. В медицинских исследованиях при установлении доверительных границ любого показателя принята вероятность безошибочного прогноза 95,5% и более. Это означает, что величина показателя, полученная на выборочной совокупности должна встречаться в генеральной совокупности как минимум в 95,5% случаев.
Вопросы по теме занятия:
Актуальность показателей разнообразия признака в статистической совокупности.
Общая характеристика абсолютных показателей вариации.
Среднее квадратическое отклонение, расчет, применение.
Относительные показатели вариации.
Медиана, квартильная оценка.
Оценка статистической значимости результатов исследования.
Стандартная ошибка средней арифметической, формула расчета, пример использования.
Расчет доли и ее стандартной ошибки.
Понятие доверительной вероятности, пример использования.
10. Понятие доверительного интервала, его применение.
Тестовые задания по теме с эталонами ответов:
1. К АБСОЛЮТНЫМ ПОКАЗАТЕЛЯМ ВАРИАЦИИ ОТНОСИТСЯ
1) коэффициент вариации
2) коэффициент осцилляции
4) медиана
2. К ОТНОСИТЕЛЬНЫМ ПОКАЗАТЕЛЯМ ВАРИАЦИИ ОТНОСИТСЯ
1) дисперсия
4) коэффициент вариации
3. КРИТЕРИЙ, КОТОРЫЙ ОПРЕДЕЛЯЕТСЯ КРАЙНИМИ ЗНАЧЕНИЯМИ ВАРИАНТ В ВАРИАЦИОННОМ РЯДУ
2) амплитуда
3) дисперсия
4) коэффициент вариации
4. РАЗНОСТЬ КРАЙНИХ ВАРИАНТ – ЭТО
2) амплитуда
3) среднее квадратичное отклонение
4) коэффициент вариации
5. СРЕДНИЙ КВАДРАТ ОТКЛОНЕНИЙ ИНДИВИДУАЛЬНЫХ ЗНАЧЕНИЙ ПРИЗНАКА ОТ ЕГО СРЕДНЕЙ ВЕЛИЧИНЫ – ЭТО
1) коэффициент осцилляции
2) медиана
3) дисперсия
6. ОТНОШЕНИЕ РАЗМАХА ВАРИАЦИИ К СРЕДНЕЙ ВЕЛИЧИНЕ ПРИЗНАКА – ЭТО
1) коэффициент вариации
2) среднее квадратичное отклонение
4) коэффициент осцилляции
7. ОТНОШЕНИЕ СРЕДНЕГО КВАДРАТИЧНОГО ОТКЛОНЕНИЯ К СРЕДНЕЙ ВЕЛИЧИНЕ ПРИЗНАКА – ЭТО
1) дисперсия
2) коэффициент вариации
3) коэффициент осцилляции
4) амплитуда
8. ВАРИАНТА, КОТОРАЯ НАХОДИТСЯ В СЕРЕДИНЕ ВАРИАЦИОННОГО РЯДА И ДЕЛИТ ЕГО НА ДВЕ РАВНЫЕ ЧАСТИ – ЭТО
1) медиана
3) амплитуда
9. В МЕДИЦИНСКИХ ИССЛЕДОВАНИЯХ ПРИ УСТАНОВЛЕНИИ ДОВЕРИТЕЛЬНЫХ ГРАНИЦ ЛЮБОГО ПОКАЗАТЕЛЯ ПРИНЯТА ВЕРОЯТНОСТЬ БЕЗОШИБОЧНОГО ПРОГНОЗА
10. ЕСЛИ 90 ВЫБОРОК ИЗ 100 ДАЮТ ПРАВИЛЬНУЮ ОЦЕНКУ ПАРАМЕТРА В ГЕНЕРАЛЬНОЙ СОВОКУПНОСТИ, ТО ЭТО ОЗНАЧАЕТ, ЧТО ДОВЕРИТЕЛЬНАЯ ВЕРОЯТНОСТЬ P РАВНА
11. В СЛУЧАЕ, ЕСЛИ 10 ВЫБОРОК ИЗ 100 ДАЮТ НЕВЕРНУЮ ОЦЕНКУ, ВЕРОЯТНОСТЬ ОШИБКИ РАВНА
12. ГРАНИЦЫ СРЕДНИХ ИЛИ ОТНОСИТЕЛЬНЫХ ВЕЛИЧИН, ВЫХОД ЗА ПРЕДЕЛЫ КОТОРЫХ ВСЛЕДСТВИЕ СЛУЧАЙНЫХ КОЛЕБАНИЙ ИМЕЕТ НЕЗНАЧИТЕЛЬНУЮ ВЕРОЯТНОСТЬ – ЭТО
1) доверительный интервал
2) амплитуда
4) коэффициент вариации
13. МАЛОЙ ВЫБОРКОЙ СЧИТАЕТСЯ ТА СОВОКУПНОСТЬ, В КОТОРОЙ
1) n меньше или равно 100
2) n меньше или равно 30
3) n меньше или равно 40
4) n близко к 0
14. ДЛЯ ВЕРОЯТНОСТИ БЕЗОШИБОЧНОГО ПРОГНОЗА 95% ВЕЛИЧИНА КРИТЕРИЯ t СОСТАВЛЯЕТ
15. ДЛЯ ВЕРОЯТНОСТИ БЕЗОШИБОЧНОГО ПРОГНОЗА 99% ВЕЛИЧИНА КРИТЕРИЯ t СОСТАВЛЯЕТ
16. ДЛЯ РАСПРЕДЕЛЕНИЙ, БЛИЗКИХ К НОРМАЛЬНОМУ, СОВОКУПНОСТЬ СЧИТАЕТСЯ ОДНОРОДНОЙ, ЕСЛИ КОЭФФИЦИЕНТ ВАРИАЦИИ НЕ ПРЕВЫШАЕТ
17. ВАРИАНТА, ОТДЕЛЯЮЩАЯ ВАРИАНТЫ, ЧИСЛОВЫЕ ЗНАЧЕНИЯ КОТОРЫХ НЕ ПРЕВЫШАЮТ 25% МАКСИМАЛЬНО ВОЗМОЖНОГО В ДАННОМ РЯДУ – ЭТО
2) нижний квартиль
3) верхний квартиль
4) квартиль
18. ДАННЫЕ, КОТОРЫЕ НЕ ИСКАЖАЮТ И ПРАВИЛЬНО ОТРАЖАЮТ ОБЪЕКТИВНУЮ РЕАЛЬНОСТЬ, НАЗЫВАЮТСЯ
1) невозможные
2) равновозможные
3) достоверные
4) случайные
19. СОГЛАСНО
ПРАВИЛУ "ТРЕХ СИГМ", ПРИ НОРМАЛЬНОМ
РАСПРЕДЕЛЕНИИ ПРИЗНАКА В ПРЕДЕЛАХ
 БУДЕТ НАХОДИТЬСЯ
БУДЕТ НАХОДИТЬСЯ
1) 68,3% вариант
Мудрые математики и статистики придумали более надежный показатель, хотя и несколько другого назначения – среднее линейное отклонение . Этот показатель характеризует меру разброса значений совокупности данных вокруг их среднего значения.
Для того, чтобы показать меру разброса данных нужно вначале определиться, относительно чего этот самый разброс будет считаться - jбычно это средняя величина. Дальше нужно посчитать, насколько значения анализируемой совокупности данных находятся далеко от средней. Понятное дело, что каждому значению соответствует некоторая величина отклонения, но нас же интересует общая оценка, охватывающая всю совокупность. Поэтому рассчитывают среднее отклонение по формуле обычной средней арифметической. Но! Но для того, чтобы рассчитать среднее из отклонений, их нужно вначале сложить. И если мы сложим положительные и отрицательные числа, то они взаимоуничтожатся и их сумма будет стремиться к нулю. Чтобы этого избежать, все отклонения берутся по модулю, то есть все отрицательные числа становятся положительными. Вот теперь среднее отклонение будет показывать обобщенную меру разброса значений. В итоге, средне линейное отклонение будет рассчитываться по формуле:
a – среднее линейное отклонение,
x – анализируемый показатель, с черточкой сверху – среднее значение показателя,
n – количество значений в анализируемой совокупности данных,
оператор суммирования, надеюсь, никого не пугает.
Рассчитанное по указанной формуле среднее линейное отклонение отражает среднее абсолютное отклонение от средней величины по данной совокупности.

На картинке красная линия - это среднее значение. Отклонения каждого наблюдения от среднего указаны маленькими стрелочками. Именно они берутся по модулю и суммируются. Потом все делится на количество значений.
Для полноты картины нужно привести еще и пример. Допустим, имеется фирма по производству черенков для лопат. Каждый черенок должен быть 1,5 метра длиной, но, что еще важней, все должны быть одинаковыми или, по крайней мере, плюс-минус 5 см. Однако нерадивые работники то 1,2 м отпилят, то 1,8 м. Дачники недовольны. Решил директор фирмы провести статистический анализ длины черенков. Отобрал 10 штук и замерял их длину, нашел среднюю и рассчитал среднее линейное отклонение. Средняя получилась как раз, что надо – 1,5 м. А вот среднее линейное отклонение вышло 0,16 м. Вот и получается, что каждый черенок длиннее или короче, чем нужно в среднем на 16 см. Есть, о чем поговорить с работниками. На самом деле я не встречал реального использования данного показателя, поэтому пример придумал сам. Тем не менее, в статистике есть такой показатель.
Дисперсия
Как и среднее линейное отклонение, дисперсия также отражает меру разброса данных вокруг средней величины.
Формула для расчета дисперсии выглядит так:
 (для вариационных
рядов (взвешенная дисперсия))
(для вариационных
рядов (взвешенная дисперсия))
 (для несгруппированных
данных (простая дисперсия))
(для несгруппированных
данных (простая дисперсия))
Где: σ 2 – дисперсия, Xi – анализируемsq показатель (значение признака), – среднее значение показателя, f i – количество значений в анализируемой совокупности данных.
Дисперсия - это средний квадрат отклонений.
Сначала рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, умножается на частоту соответствующего значения признака, складывается и затем делится на количество значений в данной совокупности.
Однако в чистом виде, как, например, средняя арифметическая, или индекс, дисперсия не используется. Это скорее вспомогательный и промежуточный показатель, который используется для других видов статистического анализа.
Упрощенный способ расчета дисперсии
![]()
Среднеквадратическое отклонение
Чтобы использовать дисперсию дл анализа данных из нее извлекают квадратный корень. Получается так называемое среднеквадратическое отклонение .

Кстати, стандартное отклонение еще называют сигмой – от греческой буквы, которой его обозначают.
Среднеквадратическое отклонение, очевидно, также характеризует меру рассеяния данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными. Как правило, среднеквадратические показатели в статистике дают более точные результаты, чем линейные. Следовательно, среднеквадратическое отклонение является более точным показателем меры рассеяния данных, чем среднее линейное отклонение.
Стандартное отклонение - классический индикатор изменчивости из описательной статистики.
Стандартное отклонение , среднеквадратичное отклонение, СКО, выборочное стандартное отклонение (англ. standard deviation, STD, STDev) - очень распространенный показатель рассеяния в описательной статистике. Но, т.к. технический анализ сродни статистике, данный показатель можно (и нужно) использовать в техническом анализе для обнаружения степени рассеяния цены анализируемого инструмента во времени. Обозначается греческим символом Сигма «σ».
Спасибо Карлам Гауссу и Пирсону за то, что мы имеем возможность пользоваться стандартным отклонением.
Используя стандартное отклонение в техническом анализе , мы превращаем этот «показатель рассеяния » в «индикатор волатильности «, сохраняя смысл, но меняя термины.
Что представляет собой стандартное отклонение
Но помимо промежуточных вспомогательных вычислений, стандартное отклонение вполне приемлемо для самостоятельного вычисления и применения в техническом анализе. Как отметил активный читатель нашего журнала burdock, «до сих пор не пойму, почему СКО не входит в набор стандартных индикаторов отечественных диллинговых центров «.
Действительно, стандартное отклонение может классическим и «чистым» способом измерить изменчивость инструмента . Но к сожалению, этот индикатор не так распространен в анализе ценных бумаг .
Применение стандартного отклонения
Вручную вычислить стандартное отклонение не очень интересно , но полезно для опыта. Стандартное отклонение можно выразить формулой STD=√[(∑(x-x ) 2)/n] , что звучит как корень из суммы квадратов разниц между элементами выборки и средним, деленной на количество элементов в выборке.
Если количество элементов в выборке превышает 30, то знаменатель дроби под корнем принимает значение n-1. Иначе используется n.
Пошагово вычисление стандартного отклонения :
- вычисляем среднее арифметическое выборки данных
- отнимаем это среднее от каждого элемента выборки
- все полученные разницы возводим в квадрат
- суммируем все полученные квадраты
- делим полученную сумму на количество элементов в выборке (или на n-1, если n>30)
- вычисляем квадратный корень из полученного частного (именуемого дисперсией )
Среднеквадрати́ческое отклоне́ние (синонимы: среднее квадрати́ческое отклоне́ние , среднеквадрати́чное отклоне́ние , квадрати́чное отклоне́ние ; близкие термины: станда́ртное отклоне́ние , станда́ртный разбро́с ) - в теории вероятностей и статистике наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания . При ограниченных массивах выборок значений вместо математического ожидания используется среднее арифметическое совокупности выборок.
Энциклопедичный YouTube
-
1 / 5
Среднеквадратическое отклонение измеряется в единицах измерения самой случайной величины и используется при расчёте стандартной ошибки среднего арифметического , при построении доверительных интервалов , при статистической проверке гипотез , при измерении линейной взаимосвязи между случайными величинами. Определяется как квадратный корень из дисперсии случайной величины .
Среднеквадратическое отклонение:
s = n n − 1 σ 2 = 1 n − 1 ∑ i = 1 n (x i − x ¯) 2 ; {\displaystyle s={\sqrt {{\frac {n}{n-1}}\sigma ^{2}}}={\sqrt {{\frac {1}{n-1}}\sum _{i=1}^{n}\left(x_{i}-{\bar {x}}\right)^{2}}};}- Примечание: Очень часто встречаются разночтения в названиях СКО (Среднеквадратического отклонения) и СТО (Стандартного отклонения) с их формулами. Например, в модуле numPy языка программирования Python функция std() описывается как "standart deviation", в то время как формула отражает СКО (деление на корень из выборки). В Excel же функция СТАНДОТКЛОН() другая (деление на корень из n-1).
Стандартное отклонение (оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии) s {\displaystyle s} :
σ = 1 n ∑ i = 1 n (x i − x ¯) 2 . {\displaystyle \sigma ={\sqrt {{\frac {1}{n}}\sum _{i=1}^{n}\left(x_{i}-{\bar {x}}\right)^{2}}}.}где σ 2 {\displaystyle \sigma ^{2}} - дисперсия ; x i {\displaystyle x_{i}} - i -й элемент выборки; n {\displaystyle n} - объём выборки; - среднее арифметическое выборки:
x ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + … + x n) . {\displaystyle {\bar {x}}={\frac {1}{n}}\sum _{i=1}^{n}x_{i}={\frac {1}{n}}(x_{1}+\ldots +x_{n}).}Следует отметить, что обе оценки являются смещёнными. В общем случае несмещённую оценку построить невозможно. Однако оценка на основе оценки несмещённой дисперсии является состоятельной .
В соответствии с ГОСТ Р 8.736-2011 среднеквадратическое отклонение считается по второй формуле данного раздела. Пожалуйста, сверьте результаты.
Правило трёх сигм
Правило трёх сигм ( 3 σ {\displaystyle 3\sigma } ) - практически все значения нормально распределённой случайной величины лежат в интервале (x ¯ − 3 σ ; x ¯ + 3 σ) {\displaystyle \left({\bar {x}}-3\sigma ;{\bar {x}}+3\sigma \right)} . Более строго - приблизительно с вероятностью 0,9973 значение нормально распределённой случайной величины лежит в указанном интервале (при условии, что величина x ¯ {\displaystyle {\bar {x}}} истинная, а не полученная в результате обработки выборки).
Если же истинная величина x ¯ {\displaystyle {\bar {x}}} неизвестна, то следует пользоваться не σ {\displaystyle \sigma } , а s . Таким образом, правило трёх сигм преобразуется в правило трёх s .
Интерпретация величины среднеквадратического отклонения
Большее значение среднеквадратического отклонения показывает больший разброс значений в представленном множестве со средней величиной множества; меньшее значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Например, у нас есть три числовых множества: {0, 0, 14, 14}, {0, 6, 8, 14} и {6, 6, 8, 8}. У всех трёх множеств средние значения равны 7, а среднеквадратические отклонения, соответственно, равны 7, 5 и 1. У последнего множества среднеквадратическое отклонение маленькое, так как значения в множестве сгруппированы вокруг среднего значения; у первого множества самое большое значение среднеквадратического отклонения - значения внутри множества сильно расходятся со средним значением.
В общем смысле среднеквадратическое отклонение можно считать мерой неопределённости. К примеру, в физике среднеквадратическое отклонение используется для определения погрешности серии последовательных измерений какой-либо величины. Это значение очень важно для определения правдоподобности изучаемого явления в сравнении с предсказанным теорией значением: если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратического отклонения), то полученные значения или метод их получения следует перепроверить. отождествляется с риском портфеля.
Климат
Предположим, существуют два города с одинаковой средней максимальной дневной температурой, но один расположен на побережье, а другой на равнине. Известно, что в городах, расположенных на побережье, множество различных максимальных дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднеквадратическое отклонение максимальных дневных температур у прибрежного города будет меньше, чем у второго города, несмотря на то, что среднее значение этой величины у них одинаковое, что на практике означает, что вероятность того, что максимальная температура воздуха каждого конкретного дня в году будет сильнее отличаться от среднего значения, выше у города, расположенного внутри континента.
Спорт
Предположим, что есть несколько футбольных команд, которые оцениваются по некоторому набору параметров, например, количеству забитых и пропущенных голов, голевых моментов и т. п. Наиболее вероятно, что лучшая в этой группе команда будет иметь лучшие значения по большему количеству параметров. Чем меньше у команды среднеквадратическое отклонение по каждому из представленных параметров, тем предсказуемее является результат команды, такие команды являются сбалансированными. С другой стороны, у команды с большим значением среднеквадратического отклонения сложно предсказать результат, что в свою очередь объясняется дисбалансом, например, сильной защитой, но слабым нападением.
Использование среднеквадратического отклонения параметров команды позволяет в той или иной мере предсказать результат матча двух команд, оценивая сильные и слабые стороны команд, а значит, и выбираемых способов борьбы.











